This web page accompanies our VMCAI 2016 submissions Pointer Race Freedom. Here you can
- find information about our prototype, and
- inspect the experiments conducted for the above submission.
Prototype
Our prototype is written in C++. All its components are implemented from scratch.
We integrated the following techniques following the approach from An Integrated Specification and Verification Technique for Highly Concurrent Data Structures:
- Data Independence
- Observer Automata
- Thread-Modular Reasoning
- Shape Analysis
In addition to an analysis for explicit memory management and garbage collection, we integrated our new ownership-respecting memory semantics. It allows for a faster analysis as we can rely on certain ownership guarantees — making thread-modular reasoning for single threads practical.
The source code can be downloaded here.
Experimental Results
For experiments we used an Intel Xeon E5-2650 v3 running at 2.3 GHz and tested our tool on the following data structure implementations:
- Coarse Stack (single lock) [Code]
- Coarse Queue (single lock) [Code]
- Treiber's lock free stack [Code]
- Micheal&Scott's lock free queue [Code]
The results are listed in the table below. The experiments were conducted on an Intel Xeon E5-2650 v3 running at 2.3 GHz. The table includes the following:
- runtime taken to establish correctness,
- number of explored thread states (i.e. size of the search space),
- number of sequential steps,
- number of interference steps,
- number of interference steps that have been pruned by an ownership-based optimization, and
- the result of the analysis, i.e. whether or not correctness could be established.
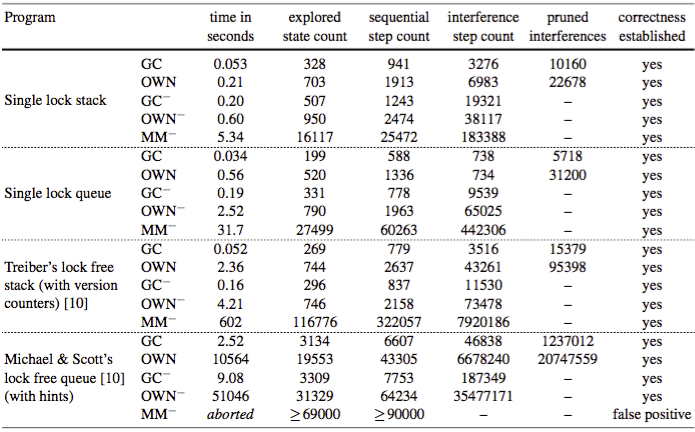
Our experiments confirm the usefulness of pointer race freedom. When equipped with pruning (OWN), the ownership-respecting semantics provides a speed-up of two orders of magnitude for Treiber's stack and the single lock data structures compared to the memory-managed semantics (MM-). The size of the explored state space is close to the one for the garbage-collected semantics (GC) and up to two orders of magnitude smaller than the one for explicit memory management.
For Michael&Scott's queue we had to provide hints in order to eliminate certain patterns of false positives. This is due to an imprecision that results from joins over a large number of states (we are using a joined representation of states based on Cartesian abstraction). Those hints are sufficient for the analysis relying on the ownership-respecting semantics to establish correctness. The memory-managed semantics produces more false positives, the elimination of which would require more hinting.
In addition to the above test we also stress tested our tool by purposely inserting pointer races, for example, by discarding the version counters. In all cases, the tool was able to detect those races. The results of those test can be found in the table below.
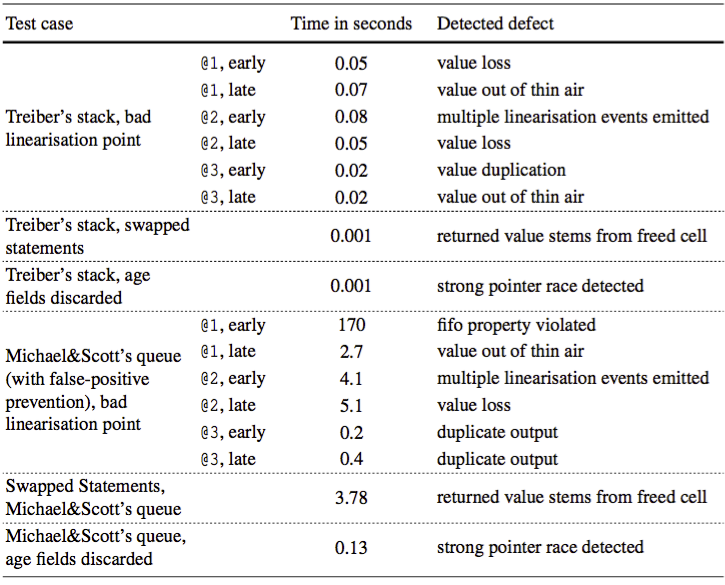
For the stress tests note the following:
- For detecting bad linearization points we added two test cases for each linearisation point were we fired the linearisation event once to early and once to late.
- In Treiber's stack we swapped the free statement with its predecessor reading out the value of the node to be freed. This allows other thread to reallocate this cell and overwrite the data that should be read and returned.
- In Michael&Scott's queue we moved the statement reading out the value after the Compare-And-Swap. This allows for reading corrupt data as some thread might free this node in between.
- Discarding the version counters (age fields) allows for the ABA problem and a strong pointer race.